Two papers of Multi-source VisualSoundLocalization(MVSL)
2021_TPMAI_CSOL
声源定位的Challenge:
targets to semantically correlate sounds with relevant visual regions without resorting to category annotations
在没有类别注释的前提下,建立起音视语义对齐
answer not only where the sounding area is but also infer what the sounding area is.
Problem
- How to discriminatively localize and recognize visual objects that belong to different categories without extra semantic annotations of objects;
- How to determine which visual objects are producing sound and filter out silent ones by referring to the corresponding mixed sound
Method
category-representation object dictionary
第一阶段使用单声源数据solo进行$AVC$代理任务,获得定位图的同时提取类级别物体表征,并存储获得object dictionary,作为类别参考,用于第二阶段的多声源定位
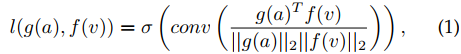
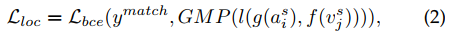
注意:
- $AVC$ 的分类loss采用的$BCE$ ,因为做的是一个正样本一个负样本的二分类
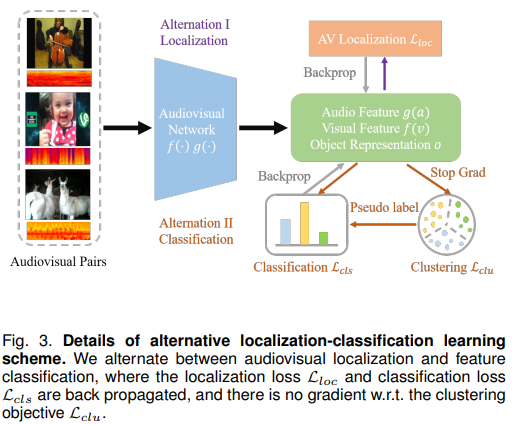
object dictionary 生成以及交替定位聚类学习
使用第一阶段得到的$AV_map$ 剔除背景区域,获得物体级别特征$o_i$
注意 $l_i \in [0,1]^{H\times W }$ , av_map是二值化mask
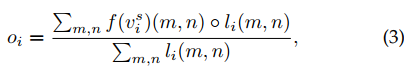
上式子就是在把$AV_map$ 乘到原特征图上,并做平均池化
得到object representation $\large O = \{o_1, o_2,…,o_{N^s} \}$
之后在 object representation 上做聚类,得到代表类别的object dictionary $D \in \mathbb{R}^{K\cdot C} $
$K-means$ 聚类
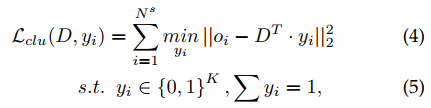
之后使用两层全连接完成分类
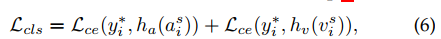
训练过程中,定位loss和分类loss交替作用,而聚类loss不起作用。聚类之起到分配标签的作用(label assignment)
distribution level audiovisual alignment
视觉上使用第一阶段的object dictionary 获得视觉类别分布,并认为这个分布和混合音频特征分布应该是一致的。
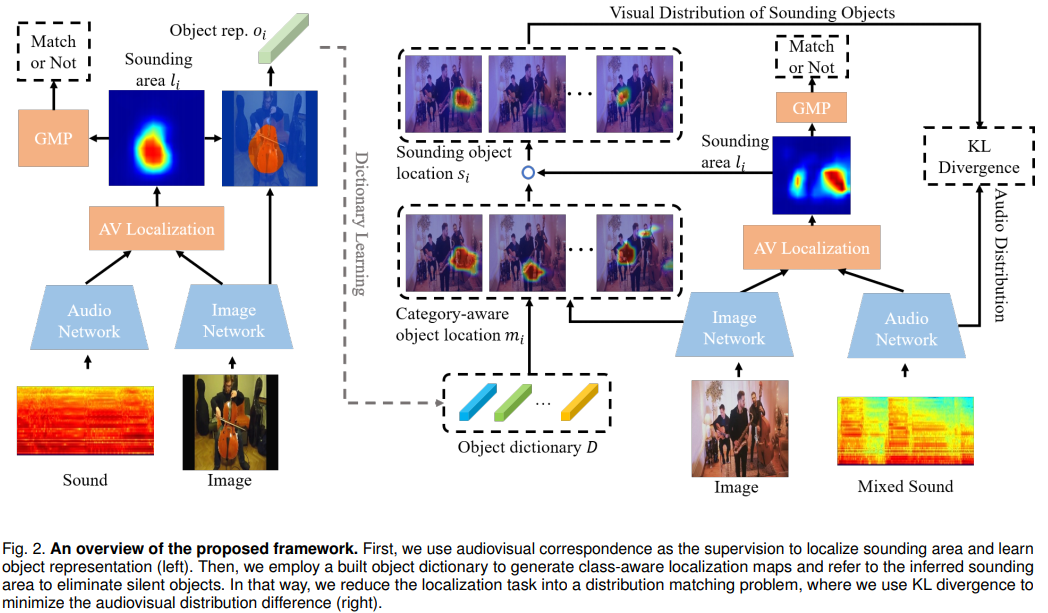
object dictionary代表每个类别的特征与多声源场景的视觉特征逐点相乘,得到各类别的激活图$m_i^k$

$l_i$ 代表粗粒度声源定位图,下面的操作是在过滤出场景各个类别激活图中是否发声
注意 $l_i \in [0,1]^{H\times W }$ , av_map是二值化mask

$l_i$ : the inferred global audiovisual localization map $l_i$ that indicates the coarse sounding area as a sounding object filter
简单来说,$l_i$ 是一个粗粒度声源定位图,$AVC$ 任务得到的,$m_i^k$ 是场景中各个物体的激活图。这个操作的意义就是让发声的物体激活值更高,不发声的激活值低。
但是有一个问题,多声源场景怎么获得粗粒度定位图?$AVC$ 理论来讲是不能在多声源场景下工作的,他没有办法去匹配多声源的视觉区域和音频,对于音视不一致的场景更加无法工作。作者在这里使用这个滤波操作是为了获得和音频特征分布一致的视觉物体特征分布,故事是通顺的,但是粗定位图是否能完成这个任务还需要商榷
使用Softmax 在多个类别上获得视觉发声物体分布。$GAP$ 是平均
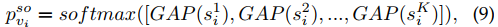
这个就是分类logist值,音频特征的。。
又有问题,softmax具有归一性,默认只有一个潜在类别,加起来和是1.但实际上音频可能存在多个类别。。。
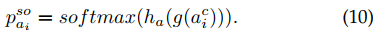
使用$KL$ 散度拉进两个分布
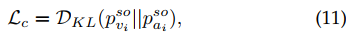
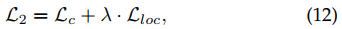
这个是为了获得class-specific 定位图 $S_i \in \mathbb{R}^{K\cdot H \cdot W} $ , 因为每个点只能属于一个类别,所以用Softmax算出来,相当于每个点打上了伪标签
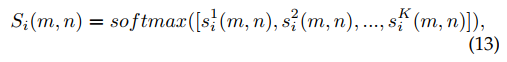
Experiment
数据集:
MUSIC,包含单声源的solo和两声源的duet。文中使用一般的solo数据进行第一阶段的训练,另一半的solo数据构造Synthetic数据集,两部分数据没有交叉。
VGGSound,本文抽出一个包含98个类别的子集作为solo,相同方式拼接得到VGGSound-synthetic
Realistic MUSIC&DailyLife dataset
2022_AAAI_IEr
Interference Eraser (IEr) 干扰消除框架
本文认为音视定位中存在 off-screen sound,background noise,audio unevenly mixed,audible but off-screen sounds and the silent but visible objects 等等干扰场景。针对这些干扰提出改进方案。
三个主要 interference:
- volume differences between mixed sound sources,
- audible but off-screen sounds,
- visible but silent objects
Method
用于stg1训练的单声源数据$\mathcal{X}^s=\{(a_i^s,v_i^s),i=1,2…,N^s\}$ 以及用于stg2训练的多声源数据$\mathcal{X}^u=\{(a_i^u,v_i^u),i=1,2…,N^u\}$
Audio Visual Prototype extraction
音视特征原型提取,即通过单声源stg1训练,对数据进行聚类,聚类中心充当类别表示,即原型Prototype,用于stg2的多声源训练阶段。
首先如下图左边,进行$AVC$ 自监督任务进行特征学习,和前作CSOL保持一致,$l(f_i^a,f_i^v)$ 就是定位图
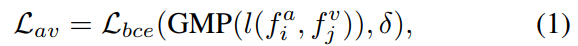
之后聚类,并得到视觉原型,visual Prototype $\mathcal{P}_j^v \in \mathbb{R}^C$ ; 所有的视觉原型表示为 $\mathcal{P}^v \in \mathbb{R}^{K\times C}$ , $C$ 代表类别数目。对音频模态进行相同的处理,可以得到音频原型$\mathcal{P}^a \in \mathbb{R}^{K\times C}$
Audio Instance Identifier
对于混合音频mix audio ebd,由于混合,可能和音频原型中的任一个都不相似;也可能由于声量,某一类别占据音频特征中的主要表现。所以本文提出Distinguishing-step 来进行区分,具体操作示意图如右下。
具体而言,使用mix-and-separate的数据构造方式。即选取单声源数据${\large a_i^{s_k}} $ $\large a_j^{s_q}$ , k!=q, 他们的one-hot类别标签已知,分别是$\mathcal{Y}_i$ $\mathcal{Y}_j$ ,则混合音频特征的标签是$\mathcal{Y}_{ij} = \mathcal{Y}_i + \mathcal{Y}_j$ . 之后做BCE分类,这算是多标签了,用BCE合理。主要训练一个区分步长distinguishing-steps $\bigtriangleup ^n(a) \in \mathbb{R}^{K\times C}$ ,这个东西会提供振幅步长,增大混合音频特征中的不显著成分。这里的话不知道为啥要提出一个区分步长的概念,就以下面的BCE loss为约束,训练特征提取器,学习$f_{ij}^a$ 不就可以了?不知道这里作者是否有特殊的实现方式。
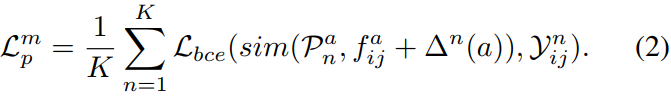
AII的课程学习策略:在单声源数据和mixed数据上交替训练,mixed数据比例为$p$ , $p$ 从0.5逐渐增加到0.9,且可以从两拼增加到四拼。这里应该就是拿聚类伪标签训练分类的过程,只不过这里还会交替训这个东西,,不过依旧好奇实现过程。
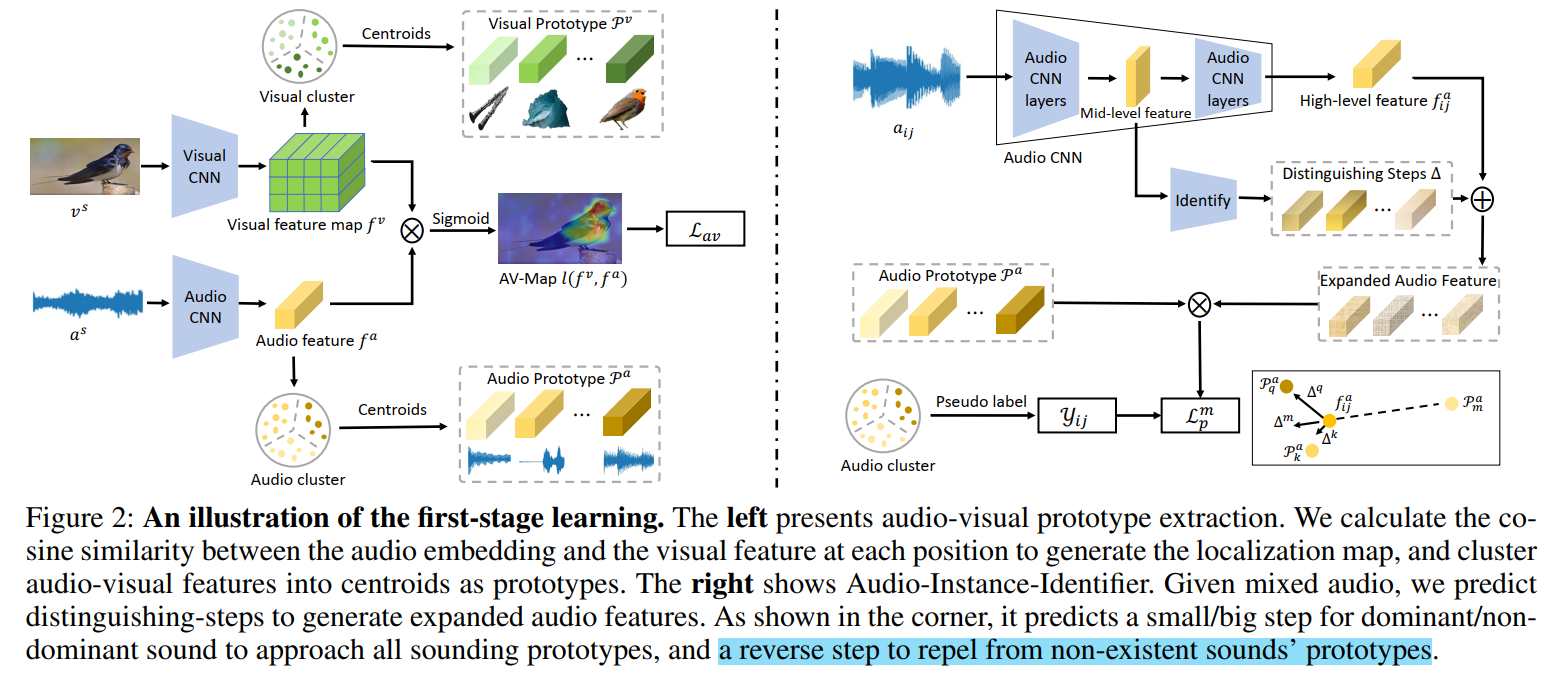
Cross modal Referrer
stg2的框架,多声源场景下定位,思路和CSOL一样,先获得发声区域AV-Map$l(f^v,F^a)$, 在获得类别物体图Class-Aware AV-Map $L^{av}$, 前两者做交集,得到类相关声源定位图Class-Specific Visual Localization Map $L^v$ 。后面还有一个跨模态分布一致loss
输入图像特征和视觉原型我们可以得到关于类别$k$ 的定位图 $L_k^v = l(f^v, \mathcal{P}_k^v)$ ; $L^v = [L_1^v,L_2^v,…,L_K^v] \in \mathbb{R}^{K\times H \times W}$
Silent Object Filter
区分步长$\bigtriangleup ^n(a) = [\bigtriangleup ^1(a)\bigtriangleup ^2(a),…, \bigtriangleup ^K(a)]$ ,之后我们得到音频特征集合$F_k^a = f^a + \bigtriangleup ^k(a) $ ; $F^a= [F_1^a, F_2^a,..,F_K^a] \in \mathbb{R}^{K\times C}$
这个有点意思了,用区分步长这个东西产生$K$ 个音频特征,等价于把混合音频特征进行了拆分。
$l(f^v,F_k^a)$ 是第$k$ 类物体的发生区域,$L_k^v$ 是第$k$ 类物体的类别物体图,乘一块解决了出镜不发声的情形。如果那个区分步长能很好的从混合音频特征中分理出各个类别的音频特征,那么推断阶段还是比较说的通的。但是怎么利用多声源数据进行训练呢?
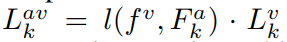
全局平均池化各个类别定位图,通过Softmax后得到视觉上的分布
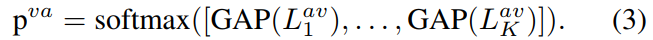
之后是音频分布,主要针对可能的发声不出镜现象。the off-screen sound
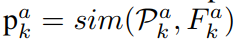
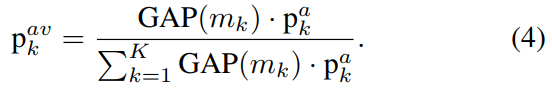

结合图和公式看,音频特征分布是通过计算加了步长的音频特征和音频原型的相似度得到的。针对发声不出镜现象,通过引入视觉二值化mask来修正。理想来看是可以解决发声不出镜的,还是比较巧妙的。
最后是一个KL散度loss
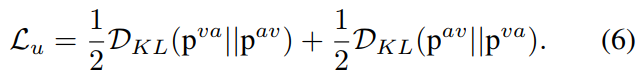
看完怎么感觉没有什么做的空间了。
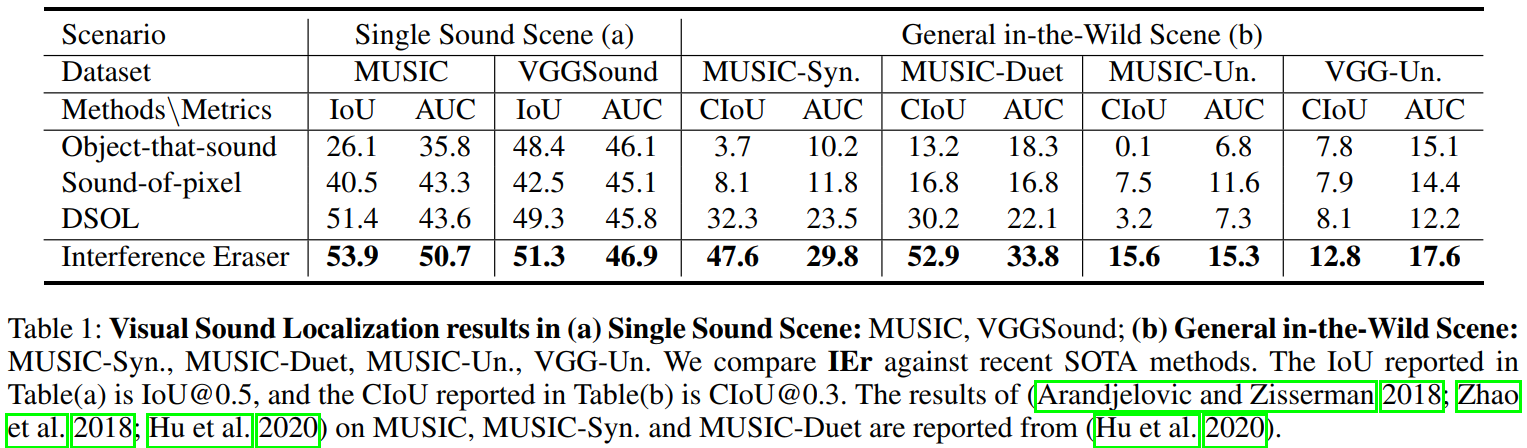
和别的论文横向对比:
在MUSIC-syn数据集上效果很好了,VGGSound数据集没有概念
Supplemental Document
Distinguishing-step 部分的细节
网络结构就是一个MLP 512-128-128
文中认为高层次的特征更加紧凑,导致不同音频特征高度叠加在一起,难以区分。所以该部分使用了中层特征最为本模块输入。
$W_n$ $b_n$ 就组成全连接层;$f_m(a_{ij})$ 就是中层特征
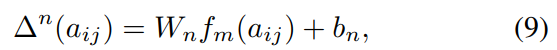
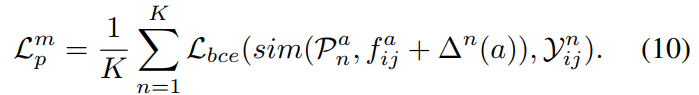
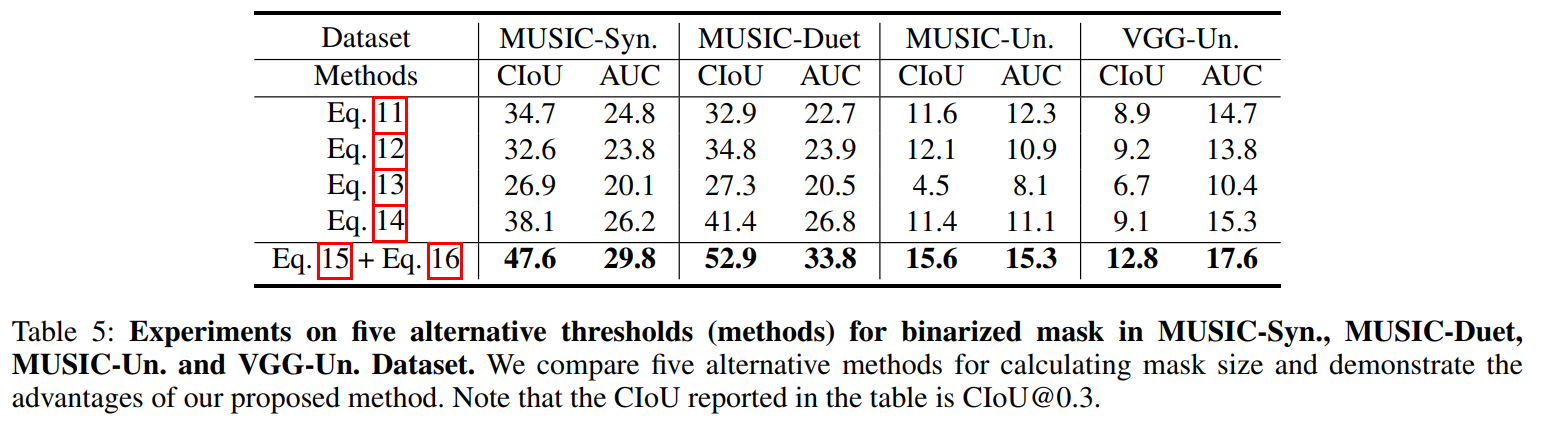
关于阈值threshold of Binarized mask的讨论
提出了五种不同方式的mask设置,用于生成 visual guide audio distribution $p^{av}$ 的计算公式
- 阈值时固定值
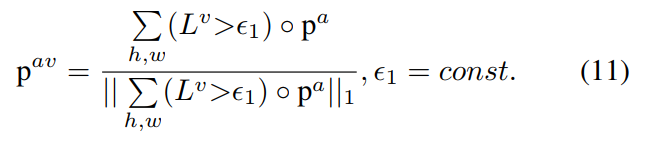
阈值取决于batch内最大响应值
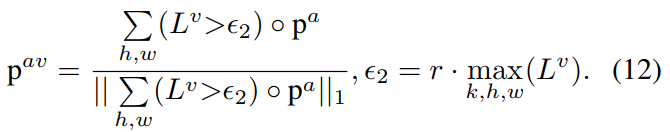
阈值取决于每张图像的最大响应值
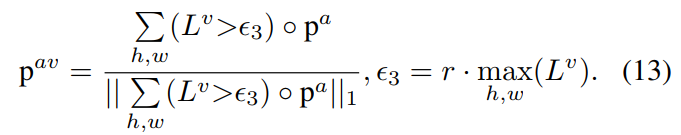
使用平均池化,直接取每张图的均值作为权重乘到$p^a$ 上
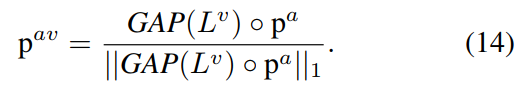
阈值由整个batch的响应均值决定

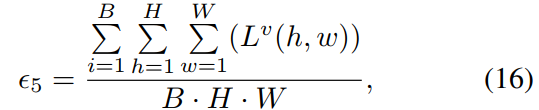
本文的future提出的现阶段声源定位框架没办法解决的难题:
1、CSOL和IEr都是针对不同类别的多声源场景进行研究的,严重依赖类别区分声源。如果是多个同类别声源,例如speech场景,会难以区分各个声源。作者还提到会引入motion来解决这个问题
2、本文框架对于特殊场景实现的定位比较粗糙,例如speech person identitification 这是由于框架没有在这些特点场景数据进行训练的缘故。。。